
話說最近剛好有解析html 的需求。 今天介紹一個工具,可以使用Java ,簡單的解析Html─Jsoup。
會選擇介紹這套framework的原因幾個:
- 仍還在持續更新
- 簡單、快速上手
- 有足夠的文件
這幾個原因也是我在選擇使用framework的一些考量。 有時候我會加上老牌(夠成熟)這樣的一個考量。 當然,通常夠成熟也會代表著不見得會在持續更新,或是更新速度已經變慢。
Jsoup不只可以解析Html,還可對Html進行一些變更後產出。Jsoup有以下一些特色:
- 可以有多種多入,包含URL、File、String。
- 有多種方式可以取得結點資訊,包含透過DOM瀏覽方式與使用CSS 的選擇器。
- 變更取得的Html原素
- 清除使用者所提交的一些資訊
- 產出所變更的Html
(來源:官網)
如何解析HTML
假設我有一個網頁:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>聊天室列表</title>
</head>
<body>
<form id="input_form">
<a href="main.html"> 回首頁 </a><br/>
<a href="next.html"> 到下一頁 </a><br/>
<input name="button" type="button" id="button" value="登出">
</form>
<table border="1">
<tr>
<td>聊天室ID</td>
<td>聊天室名稱</td>
</tr>
<tr>
<td>123456T890</td>
<td><a href="chatRoom.html">洛基</a></td>
</tr>
<tr>
<td>12X4567890</td>
<td><a href="chatRoom.html">阿波羅</a></td>
</tr>
</table>
</body>
</html>他執行起來結果看起來像這樣子:
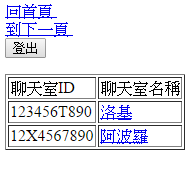
解析Html的範例程式碼會是這個樣子。
File input = new File("input.html");
Document doc = Jsoup.parse(input, "UTF-8");
Element content = doc.getElementById("input_form");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
logger.trace("link href:{}, link text:{}", linkHref, linkText);
}執行結果會是像這個樣子:
299 [TRACE] t.b.j.JsoupTest[23]: link href:main.html, link text:回首頁
302 [TRACE] t.b.j.JsoupTest[23]: link href:next.html, link text:到下一頁要注意的是Element 與 Elements 的差異。 顧名思義,Elements 可以跑迴圈。而 Document則是一個Element。 一般而言,除非像id這樣的取法,不然所搜尋出來的, 多半是Elements。
Jsoup這個tool,主要的進入點是Jsoup.parse(...)這個API。
Jsoup.parse(...)如果你已經將File轉成String,可以這樣用:
String htmlSoruce=getHtmlSource();
Document doc = Jsoup.parse(htmlSoruce);parse可以有許多種輸入,甚至可以直接輸入URL;不過似乎還無法丟參數。 更多的使用方式,當然需要詳見 API 啦。
如何取得Html物件
Jsoup取得tag的方式有很多種,使用id只是其中的一種。 也可以使用byClass、byTag。 不過我喜歡用CSS selector的方式來取得。
什麼是CSS selector? 他是一種CSS 在搜尋tag時,所使用的語法。
就如同一般指定tag的方式,CSS也有他搜尋tag的方式,來指定特定tag所要呈現的style。 CSS的搜尋語法,跟jquery似乎是一樣的。 這麼複雜的語法,跟行院的動能推動方案一樣,很難用簡單的幾句話說明,(其實我也不太會),所以各位如果有需要,可以詳參jsoup Selector的Java doc 。

CSS selector 語法要學其實不會太困難。 會的話當然好,但是如果真沒時間學習的話,我們有其他的變通方式。 後面我會介紹。
接下來,談一下範例。
比方說我想取得表格(tbody)的內容,需要先取得tbody element。 Tbody element的selector syntax是這樣:
body > table > tbody如果你閱讀程式碼的功力夠高的話,加上已經了解CSS selector語法的話,可以直接撰寫。 小弟不才,使用偷吃步的方式:
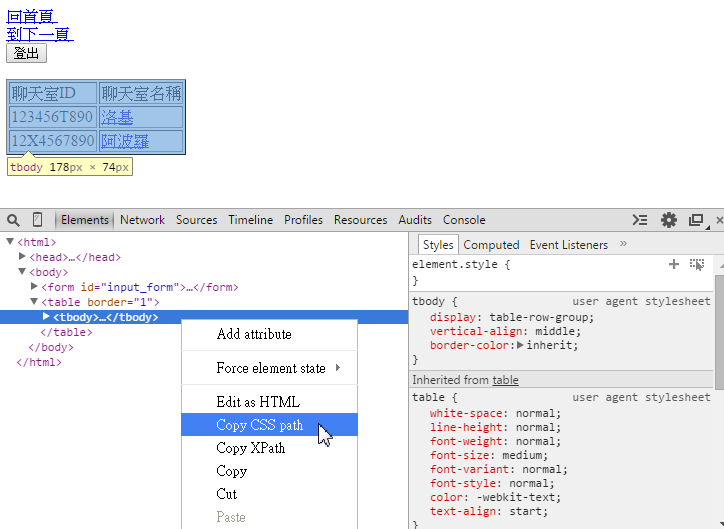
我們可以使用Google Chrome browser,點選 功能列→更多工具→開發人員工具,然後在要取得的元素上點選右鍵。
於是取得表格內容的程式碼範例會是這樣:
File input = new File("input.html");
// String htmlSoruce=getHtmlSource();
Document doc = Jsoup.parse(input, "utf-8");
Elements tbodys = doc.select("body > table > tbody");
Element tbody = tbodys.get(0);
for (Element tr : tbody.children()) {
logger.trace(tr.text());
}執行結果如下:
336 [TRACE] t.b.j.JsoupTest[23]: 聊天室ID 聊天室名稱
340 [TRACE] t.b.j.JsoupTest[23]: 123456T890 洛基
340 [TRACE] t.b.j.JsoupTest[23]: 12X4567890 阿波羅更多請參考
- 要想摸透一套工具,官網的資訊是不可獲缺的。
- 其實也有其他可以解析Html的framework,可以參考: Java-source.net。
- 你可能會留意到,明明source code沒有tbody,可是瀏覽器卻會顯示tbody。 這是因為tbody是table的必要原素,即使source code沒有,瀏覽器在處理/呈現時,還是會當他是存在的。 所以當我們在使用工具檢視原素時,還是會存在tbody這個tag,而檢視原始碼時,卻沒有這個tag。

沒有留言 :
張貼留言